

BIM, Revit, and the Database Dream
Despite being perceived as a traditional, unchanging industry, construction isn’t immune from the hype of some new technology or idea that’s poised to revolutionize the industry. In some ways, it’s actually worse in construction - because construction processes change so slowly, the hype cycle gets stretched out, and something can be the next big thing for years or even decades. Prefabrication and mass timber are two examples; BIM (Building Information Modeling) is another. A little bit of searching will yield approximately 100,000 articles about how BIM is the future of construction, stretching back to the early 2000s.
Despite-slash-because of the hype around it, it’s often very hard to untangle exactly what BIM lets you accomplish. Like with any piece of technology, popular descriptions of BIM are usually non-technical, and tend to devolve into amorphous abstractions. Autodesk describes BIM as “the holistic process of creating and managing information for a built asset”, and that “BIM integrates structured, multi-disciplinary data to produce a digital representation of an asset”. Trimble describes it as “a process of collaboration facilitated by digital technology” and that a BIM model “includes details of performance characteristics, specifications, and other non-physical data embedded in a shared 3D digital model of the project”.
Peeling back the buzzwords, we get BIM as the process of creating a digital model of the building. This often gets rounded off to “designing a building with 3D modeling tools” - whereas mechanical engineers design things with 3D modeling tools like Solidworks or Fusion, building engineers design things with 3D modeling tools like Revit or Tekla - simple!
But this conception of BIM is slightly off the mark, and misses the problem BIM was created to try to solve. To really understand BIM, we need to look at the history of how building information has been represented and communicated.
A brief history of building information
A building is typically designed by a team of architects and engineers, and then handed off to a team of contractors who will do the actual building. Because the people building it aren’t the people who designed it (and because the design team may in fact be many independent groups), designers need a way to communicate their intent to the rest of the project team - to make it clear what, exactly, should be built.
Traditionally, this was done via hand-drawn blueprints - drawings which combined a graphical representation of the building (drawings showing the floorplans, elevations, location of the various elements) and text annotations. A drawing of the foundations might show where they needed to be located and how big they should be, and have labels indicating the concrete strength, the type of reinforcing needed, how to prepare the ground prior to pouring the concrete, and so on.
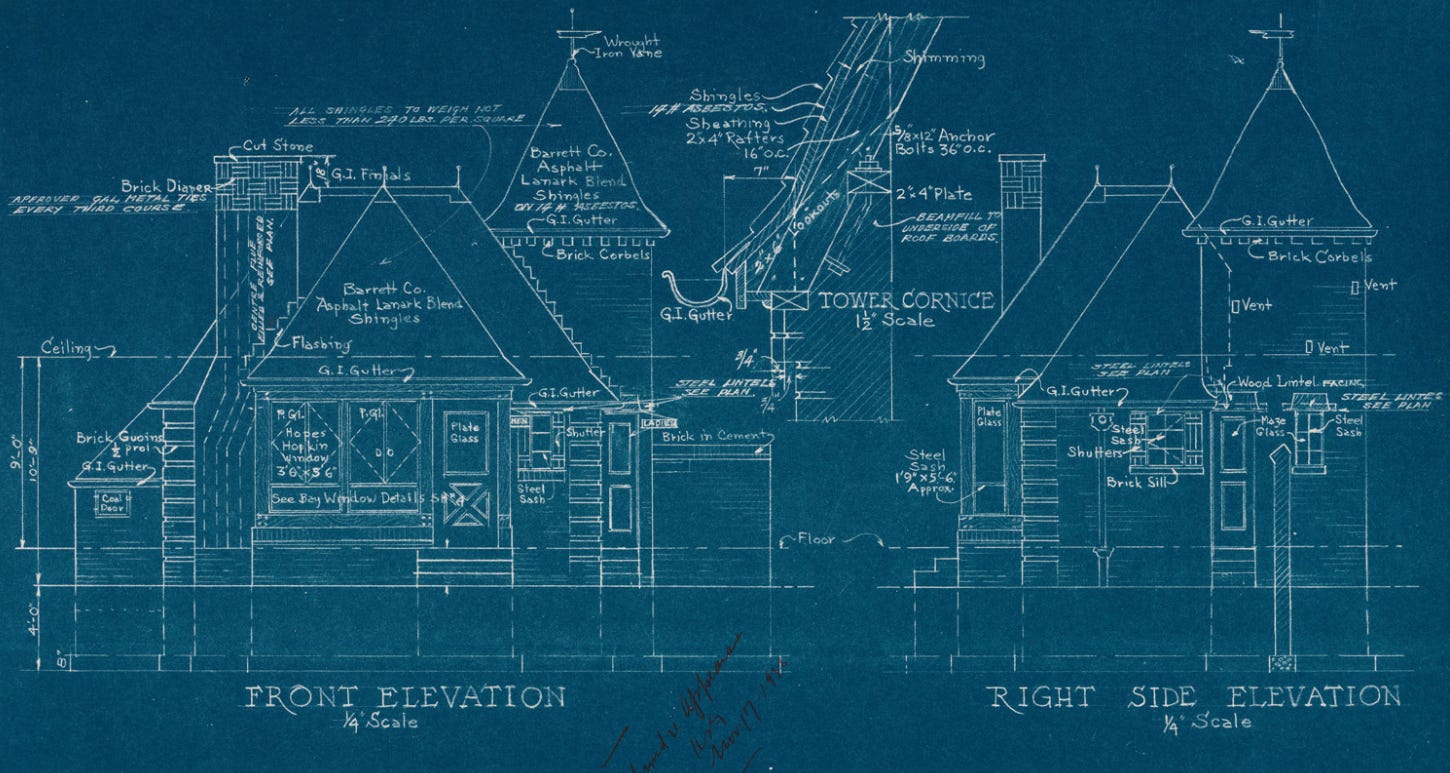
As buildings became more complex, different aspects of the building would be drawn by different disciplines - one set of drawings would show the mechanical systems, one would show the structural systems, and so on. To coordinate between the different disciplines (and increasingly complex architectural drawings), drawings would be created using a layered approach. Each drawing sheet would show one aspect of the building, and these could be layered on top of each other, either by printing them on clear Mylar sheets, or using something like a light-table, making it possible to pick and choose which aspects of the building you wanted to see.
In the 1980s, hand-drafting began to be replaced by computer drafting (the first version of AutoCAD was released in 1982). AutoCAD and other CAD tools digitized the previous paper-based process - your drawing sheets now existed in a computer file instead of as an actual sheet of paper. Drawing files were a collection of geometry - a series of lines, curves, shapes, and text, that could be assigned to different layers, and which could be turned off and on within a drawing file.
This greatly simplified the process of drawing creation (though like with any construction technology, it took a surprisingly long time to displace its predecessor), but information was still represented and communicated purely visually - you were still creating a set of drawings that would ultimately be printed out and read by the contractor. If you drew a wall, the software didn’t “know” it was a wall - all it saw was a collection of linework attached to a particular layer.
Early building information research
In parallel with the development of computer-based drafting systems, there were also CAD systems being developed that were designed to manipulate building information directly. Instead of software based around manipulating geometry (points, lines, etc.), like traditional CAD tools, these “building modeling” systems were based around the concept of structured data objects - with these sorts of tools, a wall wouldn’t just be a collection of lines, it would be a digital object that contained geometric information (size, extents, etc.) but also other information such as cost, material properties thermal properties, as well as rules for interacting with other building elements.
An example of these early efforts is the SSHA system, which began to be developed as far back as 1969. In the SSHA system, a building would be assembled from various data primitives that had geometric information, cost data, material properties, rules for combining them, etc. It had some surprisingly advanced features given for the time - it was capable of automatically producing joist layouts, and automatically calculating the amount of natural light at a location based on glazing locations.
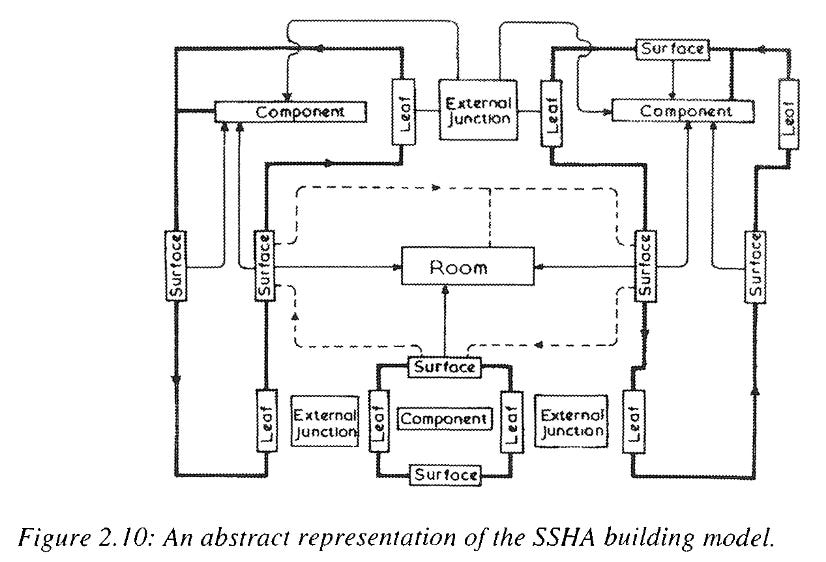
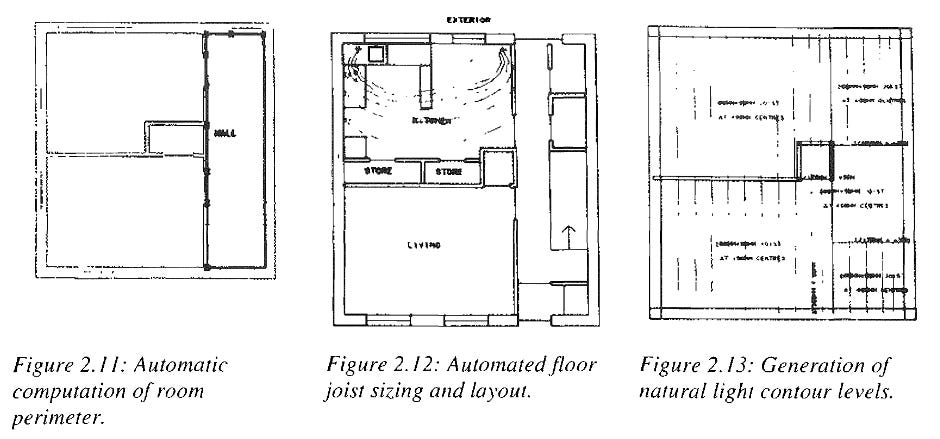
Other such systems were OXSYS (for designing British prefab hospitals), CAEDS (building design database for the US military) and GLIDE II.
These systems were focused on the problem of knowledge representation - figuring out how to use the capabilities of digital computers to store information in a useful way. Both GLIDE II and CAEDS were first and foremost databases that the user could interact with via specially designed languages to produce building specifications. The goal was to have a single building “model” - a central repository of all building information that could be accessed, viewed, and manipulated in various ways depending on the task at hand. These efforts drew heavily from other work on computer-based information structuring, such as object-oriented programming/databases, type checking, and expert systems.
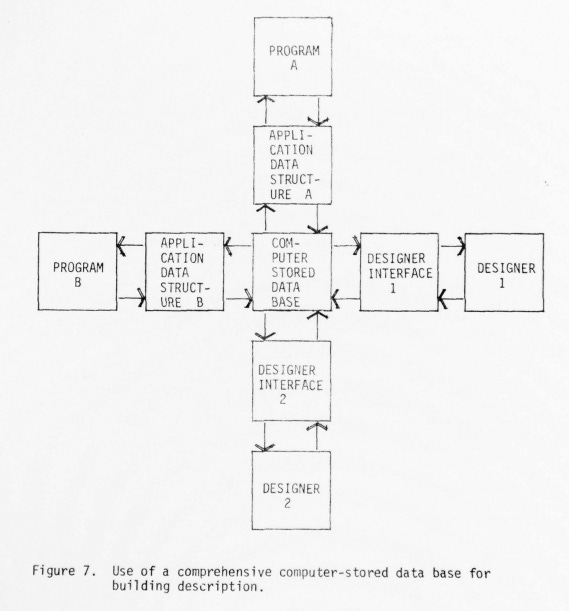
This concern about information structuring makes sense given how many thorny information problems building design entails:
The information describing a building is built up gradually, by many different people at many different times, who may or may not be able to interact with each other.
Each discipline only needs/accesses a portion of the information, but their decisions impact all the other disciplines in ways that are not always obvious (if I specify a metal strap, that may prevent the electrician from drilling through the stud to run their wiring).
Coupling between different disciplines means that the design process is fundamentally iterative; for instance, the architect’s space plan affects the structural systems, but the structural systems chosen affect what sort of space plans are feasible. Any information structure thus needs to be flexible enough to accommodate significant changes, complex dependencies, and recursive relationships.
Building information is most naturally structured hierarchically (a building contains rooms, which contain walls, which contain wall studs, etc.), but different users and trades will construct different hierarchies which won’t map cleanly onto each other. An HVAC design will break the building down into different air volumes, a structural lateral design will break it down into shear tributary areas, etc.
Much of the information in a building isn’t specified directly, but instead exists as craft expertise or traditions of practice. The architectural drawings don’t indicate where exactly each sheet of drywall needs to be placed, for instance - it’s up to the site crews to figure it out.
The thing that buildings create, usable space, isn’t constructed directly, but exists between the building elements.
These problems influenced the way modeling of building information developed - for instance, a great deal of effort was expended on figuring out “views” - ways of accessing only the information that was relevant to the task at hand, similar to how the you could overlay just the drawing sheets that you cared about in the layer-based approach.
Most of these systems remained niche or as purely academic projects, but over time commercial CAD software added capabilities for manipulating building information. AutoCAD eventually added “object CAD” features, where geometric elements could have additional building data attached to them. Pro/Engineer, a constraint based parametric mechanical design program, was released in 1988. SONATA, and its successor REfLEX (later Pro/Reflex) were building modeling programs in the late 80s/early 90s inspired by the C++ programming language, and which allowed for user-created data objects.
An early example of the potential of building design based on digital models comes from Frank Gehry (ironic, as Gehry apparently does not know how to use a computer). Gehry is famous for extraordinarily complex building exteriors, with lots of sweeping curves and few straight lines. Because his buildings were so different from standard construction practice, Gehry had difficulty dealing with contractors, who had trouble even pricing, much less building, the complex shapes, and he was often forced to compromise his designs in the name of constructability
To address this problem, in the 1990s Gehry’s firm turned to CATIA, a 3D modeling software originally built for the aerospace industry. Using CATIA, a very precise digital model was created of the building, which could then be optimized for cost (flat surfaces are cheap, single- and double-curves are expensive, so break the building into as many flat surfaces as possible). The model could then be used to generate a construction sequence, so contractors could see exactly how the building needed to be assembled. The result was that previously unconstructable designs could have their costs predicted extremely accurately, enabling the construction of buildings that might otherwise be impossible to create. This effort would ultimately be spun off into a separate company, Gehry Technologies (later acquired by Trimble).

The era of BIM
In the late 90s, these trends towards modeling buildings out of structured data objects would finally gain traction.
In 1994, Autodesk, in concert with several other building software companies, began developing “Industry Foundation Classes” (IFC), a set of standard C++ classes that would allow for data exchange between different AEC software. In 1997 it was reconstituted as a nonprofit, with the goal of defining a standard way of structuring building data and relationships. IFC theoretically allows different pieces of software to work on the same building model by exchanging IFC data. Today most BIM and AEC design software is capable of importing and exporting IFC files.
In 1997, several PTC engineers would leave to start Charles River Software, and create the first version of Revit. Revit was developed as a software for architectural design, and designed to overcome the many limitations of 2D CAD-based drawing creation.
In software such as AutoCAD, architectural drawings consisted of dozens of drawing files, each one a collection of lines, shapes, text, etc. Any change that occurred in one location (such as changing a wall type) would often need to be made in many other locations, a time consuming and error-prone process. In Revit, on the other hand, drawings were generated by creating a 3D model of the building, which could then be used to generate all the necessary drawing views. Instead of a huge collection of drawing sheets, section cuts, elevations and details which were all independent from each other, in Revit changes to the model would automatically propagate to the different elevations, section cuts, plan blow-ups, etc.
Revit was heavily influenced by the previous structured data building modeling applications (there is apparently a dispute between the founders of Revit and the designer of Reflex, regarding whether Revit was based on copied Reflex code). Buildings were assembled, not from simple geometric primitives (like most 3D modelers), but from structured data objects known as “families”. Families contained geometric data about the object in question (size, thickness, etc.) but could also include any other data the family creator wanted to include - an HVAC family might include a 3D model of a cooling unit, as well as cooling capacity, weight, manufacturer, and a link to the manufacturer’s website. Revit came with several built-in families (such as walls and windows), and allowed the user to create their own. Previous software for modeling building data, such as Reflex, required the designer to use complex programming languages to define the data objects. Revit, on the other hand, was designed to be as simple and intuitive as possible, and allowed the creation of families using drop-down menus and a simple point-and-click interface. Rather than a 3D modeler, Revit was occasionally referred to as a visual programming environment, a way of creating a building information database through a user-friendly interface.
In 2002, Autodesk acquired Revit. Their whitepaper outlining their BIM strategy remains one of the clearest explanations of what the goal of BIM is - to move from a drawing- and document-based information workflow, to one where all information about a building is stored and managed via a central database. Rather than a simple 3D modeling tool (“3D” does not appear a single time in the whitepaper; “database” occurs 23 times), BIM was intended to be a radical rethinking of how construction information was interacted with.
Where we are today
So did we get the BIM revolution that we were promised?
In a certain sense, yes. Today, Revit is everywhere in the AEC industry - somewhere around 80% of architects and engineers model their buildings in Revit, and buildings are generally designed by interacting with a shared model of the building, which allows things like clash detection. IFC (now under the purview of buildingSMART) continues to be updated, and most AEC design software supports import and export of IFC files, allowing different users with different software to all (theoretically) manipulate the same data model.
However, like so many other things in construction, the technology has made inroads in a way that doesn’t disrupt the overall process. Revit, and BIM in general, exist in a context where drawings and documents - information communicated visually - is still the primary method of information management on a construction project. Revit’s building information database is still used to generate a 2D set of non-changing drawings, and it’s these drawings that get submitted to the permitting office, get used on-site by the construction crews to put up the building, etc. And in practice, much of the data in a Revit file often consists of 2D drafting views that are essentially simple sketches, unconnected from the building model.
There’s also a huge amount of building information that gets created and manipulated entirely outside of Revit. Specifications, RFIs, shop drawings, and engineering calculations are all generally disconnected from any sort of BIM workflow.
If anything, the drawing and document workflow is becoming more entrenched, thanks to software tools that make it easier to handle the relentless flow of PDFs on a construction project. Tools like Bluebeam and Procore are built for streamlining construction information management, but are entirely predicated on a document-based workflow - Bluebeam is a fancy PDF reader with a lot of construction-specific features (like calculating areas, and letting multiple people markup the same document) and Procore is a project management tool for storing and distributing construction documents (i.e.: PDFs).
In a truly BIM-based world, where information was entirely managed by collaborating on one central database, there would be no place for this sort of document management software. But tools like this are ubiquitous, used by nearly every contractor, architect, and engineer.
We can also see the incomplete adoption of BIM in the rise of other, similar buzzwords that fill in the gaps left by BIM. VDC, “virtual design and construction” is another term that’s hard to pin down, but is basically the creation of a very accurate building model by the contractor, that’s used as an aid to the construction project. “Single Source of Truth” is a term you’ll sometimes hear on particularly complex projects, where the project is arranged so all the information gets generated from a single source - exactly what BIM was intended to be (bizarrely, a blog on Autodesk’s website has an entire article on Single Source of Truth that doesn’t mention BIM once).
What stopped BIM from taking hold completely?
Why hasn’t BIM managed to replace document-based information management? There’s a few factors at work.
Part of it is due to permitting requirements - as long as building departments require submissions to be in the form of 2D drawings (typically PDFs, but some departments still require actual paper drawings), moving away from them will be an uphill climb.
Part of it is due to software limitations. A combination of first mover advantage and strong network effects meant that BIM in many ways became synonymous with Revit, and Revit lacks features that would make it suitable for a TRULY centralized building database - it has trouble modeling some building elements at the required level of detail (such as stud walls), it lacks good ways of storing purely text-based information, it has poor tools for version control or tracking how information changes over time, it has serious compatibility issues (buildings created in one version of Revit can’t be opened in previous versions, and it’s not uncommon for designers to have 5 or 6 versions of Revit installed) - the list goes on.
There are limitations in IFC as well. It has not always handled parametric data well, and in general does not export or import data with 100% fidelity, making it difficult to use as a centralized information store.
And there are coordination costs of getting multiple parties to agree on how information should be exchanged. Buildings tend to be constructed by a different project team every time - using a central database means devoting significant time and effort to getting everyone on the same page for how data should be exchanged. The one-off nature of construction projects pushes against spending this effort, though this is likely something that could be addressed with better, more capable software.
There are also some fundamental drawbacks to using a database as the way building information is managed.
For one, a truly complete database of building information requires an enormous amount of effort to create. Even a medium-sized building might have hundreds of thousands of parts, hundreds of different specifications and standards, and an endless number of parameters to specify. Specifying all that up front would be an enormous amount of work, and also require a massive amount of ongoing maintenance to ensure that it stayed up to date. Most design professionals learn quickly to purge their drawings of unnecessary details and elements in the name of expediency and maintainability - every element you put on your drawings needs to be coordinated with every other element; every new detail is a potential error attack surface. This hasn’t changed with BIM. For buildings based on well-established construction methods and techniques, the effort to create and maintain the information in your database could easily exceed the value you can extract from it. (In practice, BIM-heavy projects tend to be large, complex ones where the cost of coordination failure makes creating and managing this information store worth it.)
For another, a database of structured information is useful for communicating with a machine, but it’s a restrictive way of mediating communication between people.
Communicating intent via drawings and text provides infinite degrees of freedom - a drawing can be any possible arrangement of lines and shapes that I think will get my point across most effectively. And that drawing can be created and transmitted using any number of possible tools - I can create it in Revit and upload it to BIM360, I can draw it in CAD and send it via email, I can sketch something on a notepad and text a picture of it (I’ve sent drawings all these ways and more).
A structured database, on the other hand, is naturally much more constricting - I’m forced to figure out how to arrange the information I want to send in a way that the database understands, and the person on the other end must do the same. And since any construction information will bottom out with a person on the jobsite performing some task, in practice this tends to simply add a layer of communication overhead rather than simplifying the process. With drawings, on the other hand, there's almost zero barrier between thinking of information and communicating it.
The Future of BIM
This suggests that BIM will become more prevalent as machines take a greater role in the construction process.
Of the various technologies with the potential to do this (prefabrication, on-site robots, etc.) I think the one likely to have the greatest effect is AR/VR. This has such obvious construction potential that it seems impossible that it won’t become ubiquitous on jobsites, and thus require the creation of much more robust building data models. As AR/VR comes down in price and gains capabilities, we may see it pull forward BIM adoption.
(Thanks to Jeffrey McGrew for the initial discussion which led to this article).
Feel free to contact me!
email: briancpotter@gmail.com
linkedin: https://www.linkedin.com/in/brian-potter-6a082150/
To expand on your "every new detail is a potential error attack surface" remark, fear/risk of litigation is another key obstacle preventing BIM from taking hold completely. The actual contract documents are almost always 2D. Designers may send 3D models to the contractor, but only after the contractor signs a release acknowledging that the drawings are the source of truth.
I believe this is due to the lack of change control and potential for ambiguity in BIM. Revision clouds provide straightforward change control for 2D documents. In the case of a dispute, 2D drawings make it easy to see exactly what the design team provided to the contractor; the contract line is clear. Not so for BIM. Even if you can effectively enshrine a specific model version as the single source of contract truth (no small feat), models contain so much information that it's difficult to clearly communicate the design intent. E.g. between different worksets, design options, links, views, hidden elements, etc. there will inevitably be some confusion regarding design intent.
Said another way, designers are well-practiced at quality control and CYA in 2D drawings but BIM allows too many loopholes.
The Gehry Technologies example you mention above is the exception that proves the rule. Seattle's Experience Music Project (now "MoPop"), built way back in the mid/late 90's (!!!), lived the BIM dream: the Catia model was the source of truth, contractually and in practice. I have heard that the model was so detailed it contained the screws securing the light switch face plates. This ultra-detailed model was at the center of an atypical contract that included a ~20-step flowchart detailing the project's information flows. I suspect that this worked because the owner had deep enough pockets to A) pay for team members to hire Catia specialists from Boeing and B) make sure all parts of the team made money, reducing the overall risk/litigiousness.
Perhaps BIM's fate is tied to that of another perennial next-big-thing: Integrated Project Delivery (IPD).
Another proposed benefit of BIM that I see pushed--my slice of the world is heavy civil works (dams, etc.) for the US Government--is the ability to keep the BIM database as a single source of truth through the project life, assisting in maintenance and further work. That is, if you want to do a contract for maintenance work or modifications for new requirements, you can use the BIM system to support that work and to create new contracts.
The problem with this workflow is that now, somebody has to maintain that model throughout the life of the project, and without that effort the model can turn out to be worse than useless. We've been 3D for years, though not BIM, and we've found that even the dumb 3D geometry can be very fraught for reuse. When you go into project files and pull a 3D model to start a new job, *exactly* how much do you trust what that model says? In several instances, we've ended up creating a whole new 3D model for newer modification contracts, just because we couldn't be sure of the accuracy of the model created, say, 10 years prior for another job, and doing detailed checking against the drawings to validate the model can be as extensive an effort as creating a new one. (And even opening something that old can be a real challenge, given that backwards compatibility doesn't always seem to be a priority for software--paper, and to a lesser extent PDFs and images, always work in the future unlike gee-whiz tools.)
Granted, we have a very different environment than what you're discussing here. Almost everything I've worked on is modification to an existing site from decades before computers were widespread, rather than new-build. This does make it even more challenging overall, because instead of a model done right at construction that you can reasonably be sure was complete like what you're discussing in the OP, budget limits often mean a model was created just with the extents of the work and maybe a little bit beyond, and the limits of the work where more detailed effort was put in won't always be obvious to a future design team.
For example, I've been working on a project modifying an intake tower for a dam (think "underwater skyscraper", which draws water into outlet works and a powerhouse and has infrastructure to access the gates way down in the depths of the reservoir so you can perform that work in the dry). The modifications were mostly occurring on one exterior face. We had no 3D model for the existing structure, so we had a technician start creating a model from the as-built sets, which consisted of two large projects (the original construction in the '50s, and a major modification in the late '90s). However, since we were only modifying one side, most of the effort in modeling the 3D geometry went into the area we were modifying. For example, just due to timeline and budget limitations, I told the technician to not model stairways and very significant steel platforms inside the tower because we weren't touching them. Even the water passages we elected to just stop modeling about 5' from where they leave the tower.
But that means that if somebody wants to use this model in the future for modifications inside the tower, they'll have to know that it's incomplete and what was left incomplete. My technician is very good about making sure he does one two things: 1) model something completely accurately to the as-built drawings, or 2) not model it at all. This does mean that, say, for the stairways a future user will see them missing and know they have to be modeled. (The missing platforms are something they'll have to know about, though.) However, not everybody is like this! Some people, in the past, have done stuff like just fake in stairway geometry since they're not going to touch it so it "looks right" on e.g., section cuts, and that's not always immediately apparent. So you have to approach a model with a healthy sense of distrust.
The other limitation, which may be similar to what you see in the private sector, is that the people who are technically responsible for maintenance of "as-builts," to include any models, would be our Operations staff, who are in a position very similar to Owners in this respect. But if they're not making sure that *everybody* touching the works in the model actually *uses* the model, to include their own maintenance personnel, even a technically-complete model can drift significantly. Generally for smaller work there's a tendency to just do a new small set of drawings for modifications, or for very small stuff, to just redline the existing sheets. But they're unlikely to put in the effort to then feed this back into the model, so no matter what you're not getting away from extensive reliance on integrating multiple sets of drawings as part of the work.
Not to say that this is just a problem for 3D models/BIM, of course! You run into integration, unknown modifications in the past, and as-built differences in paper drawings. It may just be me used to working with paper drawings, but it "feels" harder to find these differences in a full model, since as you noted you can radically change what you see via different views.
But it's much cheaper and easier to work with the paper drawings using the Mk1 Eyeball, as opposed to groveling through a 3D model to figure out what's going on. The question is, "Will this become cheap and easy enough to make it worthwhile to transition to a model as the main way of maintaining data?" We've kicked around transitioning to BIM in our office for years, but as you've noted, there's a real resistance to change, in this case, because of the possibility of spending a bunch of money and not actually ending up with a workable product. The only way to be sure to succeed is to spend a huge amount of money creating models and the infrastructure to maintain them, but that also means that if you fail you've wasted huge amounts of money, and those of us working in government service aren't unaware of how bad we are at IT as an organization.
I'm not sure how well many private owners can really do this either; having a guy maintaining and managing a Revit model feels harder and more expensive than having a set of cabinets in the basement with paper drawings, or even maintaining a folder on a hard drive with PDFs or scanned images. Admittedly, I'm limited here because all of my experience is in the federal government with very different constraints and internal politics.