

How Much Computing Power is in a Data Center?
Every day there’s some new story about the enormous amounts of investment in building AI data centers. The Wall Street Journal reports that, as a fraction of GDP, AI capital spending in 2026 alone will be more than was spent on the decade-long build-up of the national railroad system, federal expenditures to create the interstate highway system, or the entire Apollo program. Bloomberg reports that AI data center spending might reach as much as $3 trillion. The Electric Power Research Institute is projecting that data centers will consume up to 17% of all US electricity by 2030.
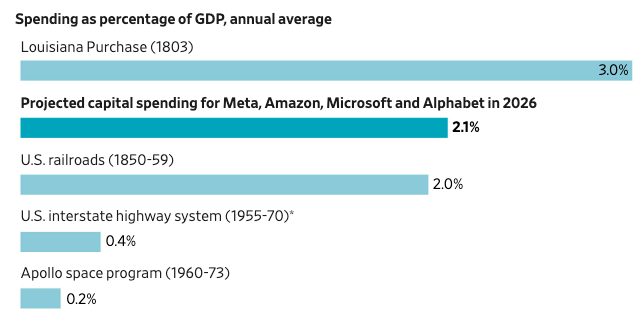
But talking about data centers in terms of dollars spent or power consumed is somewhat abstract: it doesn’t tell us much about the sort of capabilities of the infrastructure we’re actually building, the way that “miles of track” or “miles of highway” tells us about the scale of railroad or interstate building. I wanted to get a better understanding of what the data center buildout looks like in terms of computational power.
AI and computation
By far the biggest drivers of the AI data center buildout are scaling laws. Briefly, the more data you use to train an AI model, and the bigger and more computationally expensive that model is, the better the model performs. Making better and more powerful AI models thus demands increasing amounts of computation to train and run them, and data centers are where all that computation is done.
A common measure of AI model computing power is FLOPS, floating-point operations per second. OpenAI’s GPT-2 model took an estimated 2.3x10^21 FLOP to train, while the more advanced GPT-4 took an estimated 2.1x10^25 FLOP — almost 10,000 times as much computation as GPT-2, more than 20 trillion trillion operations.
(There is, of course, much more to computer performance than just FLOPS, but it’s a useful measure of computing power and it’s what we’ll stick with here.)
A floating-point operation is exactly what it sounds like: a mathematical operation (addition, subtraction, multiplication, division) performed on floating-point numbers. A floating-point number is a way of digitally representing fraction or decimal numbers in a computer, which stores everything as a sequence of ones and zeroes. It typically has three parts: a sign (whether the number is positive or negative), and a significand (some sequence of digits) multiplied by a base raised to an exponent (which locates the decimal point).
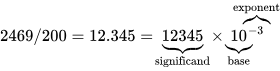
Different standards for encoding floating-point numbers in different amounts of memory allocate a different amount of space for each of these parts. For example, the IEEE 754 standard for floating-point arithmetic specifies a 32-bit floating-point number (the size of floating-point numbers typically used in general-purpose computers) as having 1 bit for the sign, 8 bits for the exponent, and 23 bits for the significand. This finite amount of space makes floating-point operations fundamentally limited in their precision, because the less space you allocate, the less precise your number. A 16-bit floating-point number will have less precision than a 32-bit one, which will have less precision than a 64-bit one. (This will become important later.)

So how many FLOPS can a typical AI data center achieve?
Computation in a data center is done on huge numbers of graphics processing units, or GPUs, which are specialized computers designed to perform large numbers of arithmetic operations simultaneously. (GPUs were originally designed to render graphics for things like computer gaming, and for many years Nvidia was primarily a manufacturer of computer gaming graphics cards.) One common GPU is Nvidia’s H100, which was first released in 2022 and is still one of the most popular GPUs for AI-related computing tasks. Estimates of data center capacity will often be done in terms of “H100 equivalents.” Per Epoch AI’s dataset on large GPU clusters, a typical AI data center will have around 100,000 H100 equivalents, and a very large one might have 1 million or more. Meta’s planned 5-gigawatt data center campus in Louisiana is estimated to have over 4 million H100 equivalents when it’s complete.
How much computational capacity does an H100 have?
This is where it starts to get complex. GPUs designed for AI tasks, like the H100, are able to perform more computation on less precise numbers. For a typical 32-bit floating-point number (FP32), an H100 can do 60–67 teraFLOPS depending on the configuration: up to 67 x 10^12, or 67 trillion, floating-point operations per second. But with 16-bit numbers (FP16), an H100 can achieve 1,979 teraFLOPS, an increase of almost 30 times. And with 8-bit floating-point numbers (FP8), it can double that again to 3,958 teraFLOPS.
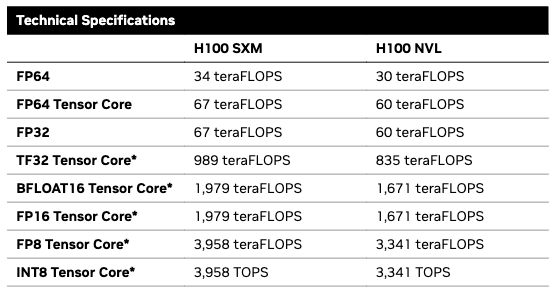
However, outside of FP32 and FP64, these performance levels are achieved with something called sparsity. Sparsity occurs when for a group of four values in a matrix, at least two of them are zero. When this occurs, the GPU can skip multiplications of the zero values, effectively cutting in half the number of operations it must perform. If the matrix isn’t sparse (if the matrix is dense), the listed performance numbers will fall by roughly half.
When training an AI model, sparsity basically can’t be achieved at all. When running a model it can be, but taking advantage of it requires putting the model through an extra step known as pruning. So only in certain cases can these published H100 performance levels actually be reached.
Most general-purpose computing is done using higher-precision FP32 floating-point numbers. But for training and running AI models, it turns out that good results can be achieved with 16-bit, 8-bit, or even 4-bit floating-point numbers.
How does the computational capacity of an H100 compare to other types of computer, say, an iPhone?
The iPhone 16 uses Apple’s A18 chip and features a six-core GPU on the Pro version. Estimates of the computational capacity of the A18 vary, but it seems to be on the order of 2–3 teraFLOPS using FP32, and perhaps double that using FP16. The A18 also has a 16-core neural processing unit (NPU) capable of 35 trillion operations per second (TOPS) with what appears to be 8-bit integers (INT8). By comparison, the H100 can do up to 3,958 TOPS at INT8 with sparsity, an increase of 113 times. (The A18 also has a CPU, but this apparently adds a negligible amount of computational capacity.)
To put this all together: an H100 has 20–30 times the computational capacity of an iPhone 16 GPU when it’s doing mathematical operations with 32-bit floating-point numbers, but around 137-275 times the capacity when working with 16-bit numbers (depending on whether you have sparsity or not). And an H100 has around 56-113 times the capacity of the A18’s NPU. If we assume that both the NPU and GPU can be used together, this suggests an H100 has on the order of 50-100 times the computational capacity of an iPhone 16.1 A typical AI data center with 100,000 H100 equivalents will be roughly equivalent to 5-10 million iPhone 16s, and a monstrous 5 GW data center will be equivalent to 200-400 million (!) iPhone 16s.
Of course, in practice you couldn’t achieve anything like an H100 performance by wiring a bunch of iPhones together; the H100 is designed to be connected to thousands of other H100s, and has massive interconnect and memory bandwidth to make that possible, which the iPhone doesn’t. But this gives us a rough idea of the computational capacities involved.
Another comparison: An H100 has about 80 billion transistors, whereas an A18 has about 20 billion.
A question I have: What is the depreciation going to be on these data centers? The infrastructure will likely continue to be useful in some way, but presumably the silicon will be worthless in a couple of years?
Thank you for this - very useful!!
I'd also love to see an article with an estimate of the resources to build a data center filled with computers--including the metals and other materials that must be mined, the waste rock generated, the energy required to mine and refine and manufacture the computers, and of course the same for the communications, cooling systems, and energy systems to power them, and the massive data center buildings themselves. The construction of all of this is fascinating from a materials and supply chain perspective. Thank you!!