

Information and Technological Evolution
I spend a lot of time reading about the nature of technological progress, and I’ve found that the literature on technology is somewhat uneven. If you want to learn about how some particular technology came into existence, there’s often very good resources available. Most major inventions, and many not-so-major ones, have a decent book written about them. Some of my favorites are Crystal Fire (about the invention of the transistor), Copies in Seconds (about the early history of Xerox), and High-Speed Dreams (about early efforts to build a supersonic airliner).
But if you’re trying to understand the nature of technological progress more generally, the range of good options narrows significantly. There’s probably not more than ten or twenty folks who have studied the nature of technological progress itself and whose work I think is worth reading.
One such researcher is Brian Arthur, an economist at the Santa Fe Institute.1 Arthur is the author of an extremely good book about the nature of technology (called, appropriately, “The Nature of Technology,”) which I often return to. He’s also the co-author, along with Wolfgang Polak, of an interesting 2006 paper, “The Evolution of Technology within a Simple Computer Model,” that I think is worth highlighting. In this paper Arthur evolves various boolean logic circuits (circuits that take ones and zeroes as inputs and give ones and zeroes as outputs) by starting with simple building blocks and gradually building up more and more complex functions (such as a circuit that can add two eight-bit numbers together).
I wanted to highlight this paper because I think it sheds some light on the nature of technological progress, but also because the paper does a somewhat poor job of articulating the most important takeaways. Some of what the paper focuses on — like the mechanics of how one technology gets replaced by a superior technology — I don’t actually think are particularly illuminating. By contrast, what I think is the most important aspect of the paper — how creating some new technology requires successfully navigating enormous search spaces — is only touched on vaguely and obliquely. But with a little additional work, we can flesh out and strengthen some of these ideas. And when we look a little closer, we find what the paper is really showing us is that finding some new technology is a question of efficiently acquiring information.
Outline of the paper
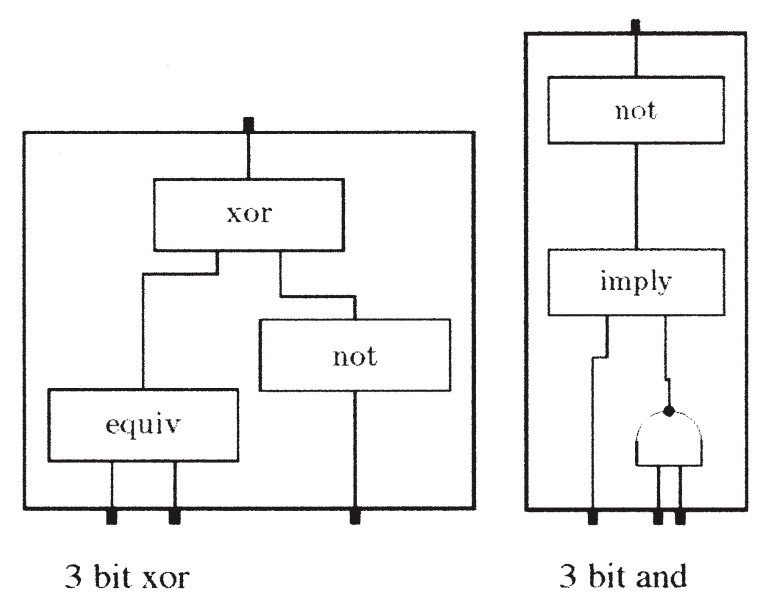
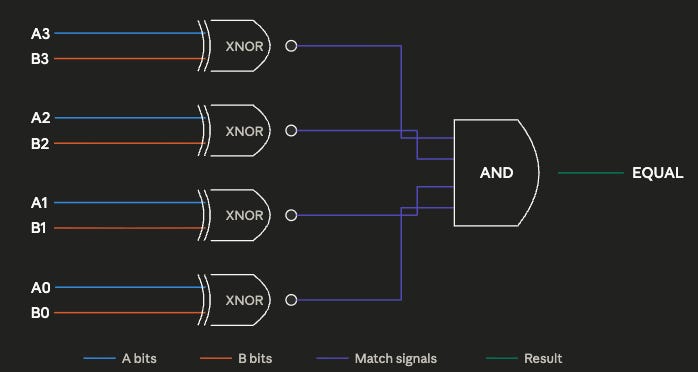
The basic design of the experiment is simple: run a simulation that randomly generates various boolean logic circuits and analyze the sort of circuits that the simulation generates. Boolean logic circuits are collections of various functions (such as AND, OR, NOT, EQUAL) that perform some particular operation on binary numbers. The logic circuit below, for instance, determines whether two 4-bit numbers are equal using four exclusive nor (XNOR) gates, which output a 1 if both inputs are identical, and a 4-way AND gate, which outputs a 1 if all inputs are 1. Boolean logic circuits are important because they’re how computers are built: a modern computer does its computation by way of billions and billions of transistors arranged in various logic circuits.
The simulation works by starting with three basic circuit elements that can be included in the randomly generated circuits: the Not And (NAND) gate (which outputs 0 if both inputs are 1, and 1 otherwise), and two CONST elements which always output either 1 or 0. The NAND gate is particularly important because NAND is functionally complete; any boolean logic circuit can be built through the proper arrangement of NAND gates.
Using these starting elements, the simulation tries to build up towards higher-level logical functions. Some of these goals, such as creating the OR, AND, and exclusive-or (XOR) functions, are simple, and can be completed with just a few starting elements. Others are extremely complex, and require dozens of starting elements to implement: an 8-bit adder, for instance, requires 68 properly arranged NAND gates.
To achieve these goals, during each iteration the simulation randomly combines several circuit elements — which at the beginning are just NAND, one, and zero. It randomly selects between two and 12 components, wires them together randomly, and looks to see if the outputs of the resulting circuit achieve any of its goals. If it has — if, by chance, the random combination of elements has created an AND function, or an XOR function, or any of its other goals — that goal is marked as fulfilled, and circuit that fulfills it gets “encapsulated,” added to the pool of possible circuit elements. Once the simulation finds an arrangement of NAND components that produces AND and OR, for instance, those AND and OR arrangements get added to the pool of circuit elements with NAND and the two CONSTS. Future iterations thus might accidentally stumble across XOR by combining AND, OR, and NAND.
Because finding an exact match for a given goal might be hard, especially as goals get more complex, the simulation will also add a given circuit to the pool of usable components if it partially fulfills a goal, as long as it does a better job of meeting that goal than any existing circuit. Circuits that partially meet some goal (such as a 4-bit adder that gets just the last digit wrong) are similarly used as components that can be recombined with other elements. So the simulation might try wiring up our partly-correct 4-bit adder with other elements (NAND, OR, etc.) to see what it gets; maybe it finds another mini-circuit that can correct that last digit.
Over time, the pool of circuit elements that the simulation randomly draws from grows larger and larger, filled both with circuits that completely satisfy various goals and some partly-working circuits. A circuit can also get added to the pool if it’s less expensive — uses fewer components — than existing circuits for that goal. So if the simulation has a 2-bit adder made from 10 components, but stumbles across a 2-bit adder made from 8 components, the 8-component adder will replace the 10 component one.
When the simulation is run, it begins randomly combining components, which at the beginning are just NAND, one, and zero. At first only simple goals are fulfilled: OR, AND, NOT, etc. The circuits that meet these goals then become building blocks for more complex goals. Once a 4-way AND gate is found (which outputs 1 only if all its inputs are 1), that can be used to build a 5-way AND gate, which in turn can be used to build a 6-way AND gate. Over several hundred thousand iterations, surprisingly complex circuits can be generated: circuits which compare whether two 4-bit numbers are equal, circuits which add two 8-bit numbers together, and so on.
However, if the simpler goals aren’t met first, the simulation won’t find solutions to the more complex goals. If you remove a full-adder from the list of goals, the simulation will never find the more complex 2-bit adder. Per Arthur, this demonstrates the importance of using simpler technologies as “stepping stones” to more complex ones, and how technologies consist of hierarchical arrangements of sub-technologies (which is a major focus of his book).
We find that our artificial system can create complicated technologies (circuits), but only by first creating simpler ones as building blocks. Our results mirror Lenski et al.’s: that complex features can be created in biological evolution only if simpler functions are first favored and act as stepping stones.
Analyzing this paper
I don’t have access to the original simulation that Arthur ran, but thanks to modern AI tools it was relatively easy for me to recreate it and replicate many of these results. Running it for a million iterations, I was able to build up to several complex goals: 6-bit equal, a full-adder (which adds 3 1-bit inputs together), 7-bitwise-XOR, and even a 15-way AND circuit.

But I also found that not all of the simulation design elements from the original paper are load-bearing, at least in my recreated version. In particular, much of the simulation is devoted to the complex “partial fulfillment” mechanic, which adds circuits that only partially meet goals, and gradually replaces them as circuits that better meet those goals are found. The intent of this mechanic, I think, is to make it possible to gradually converge on a goal by building off of partly-working technologies, which is how real-world technologies come about. However, when I turn this mechanic off, forcing the simulation to discard any circuit that doesn’t 100% fulfill some goal, I get no real difference in how many goals get found: the partial fulfillment mechanic basically adds nothing (though this could be due to differences in how the simulations were implemented).
To me the most interesting aspect of this paper isn’t showing how new, better technologies supersede earlier ones, but how the search for a new technology requires navigating enormous search spaces. Finding complex functions like an 8-bit adder or a 6-bit equal requires successfully finding working functions amidst a vast ocean of non-working ones. Let me show you what I mean.
We can define a particular boolean logic function with a truth table – an enumeration of every possible combination of inputs and outputs. The truth table for an AND function, for instance, which outputs a 1 if both inputs are 1 and 0 otherwise, looks like this:
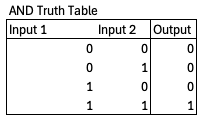
Every logic function will have a unique truth table, and for a given number of inputs and outputs there are only so many possible logic functions, so many possible truth tables. For instance, there are only four possible 1 input, 1 output functions.
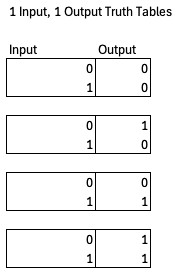
However, the space of possible logic functions gets very very large, very very quickly. For a function with n inputs and m outputs, the number of possible truth tables is (2^m)^(2^n). So if you have 2 inputs and 1 output, there are 2^4 = 16 possible functions (AND, NAND, OR, NOR, XOR, XNOR, and 10 others). If you have 3 inputs and 2 outputs, that rises to 4^8 = 65,536 possible logic functions. If you have 16 inputs and 9 outputs, like an 8-bit adder does, you have a mind-boggling 10^177554 possible logic functions. By comparison, the number of atoms in the universe is estimated to be on the order of 10^80, and the number of milliseconds since the big bang is on the order of 4x10^20. Fulfilling some goal from circuit space means finding one particular function in a gargantuan sea of possibilities.
The question is, how is the simulation able to navigate this enormous search space? Arthur touches on the answer — proceeding to complex goals by way of simpler goals — but he doesn’t really look deeply at the combinatorics in the paper, or how this navigation happens specifically.2
The emergence of circuits such as 8-bit adders seems not difficult. But consider the combinatorics. If a component has n inputs and m outputs there are (2^m)^(2^n) possible phenotypes, each of which could be realized in a practical way by a large number of different circuits. For example, an 8-bit adder is one of over 10^177,554 phenotypes with 16 inputs and 9 outputs. The likelihood of such a circuit being discovered by random combinations in 250,000 steps is negligible. Our experiment— or algorithm—arrives at complicated circuits by first satisfying simpler needs and using the results as building blocks to bootstrap its way to satisfy more complex ones.
Navigating large search spaces
In his 1962 paper “The Architecture of Complexity,” Nobel Prize-winning economist Herbert Simon describes two hypothetical watchmakers, Hora and Tempus. Each makes watches with 1000 parts in them, and assembles them one part at a time. Tempus’ watches are built in such a way that if the watchmaker gets interrupted — if he has to put down the watch to, say, answer the phone — the assembly falls apart, and he has to start all over. Hora’s watches, on the other hand, are made from stable subassemblies. Ten parts get put together to form a level 1 assembly, ten level 1 assemblies get put together to form a level 2 assembly, and 10 level 2 assemblies get put together to form the final watch. If Hora is interrupted in the middle of a subassembly, it falls to pieces just like Tempus’ watches, but once a subassembly is complete it’s stable; he can put it down and move on to the next assembly.
It’s easy to see that Tempus will make far fewer watches than Hora. If both have a 1% chance of getting interrupted each time they put in a part, Tempus only has a 0.99 ^ 1000 = 0.0043% chance of assembling a completed watch; the vast majority of the time, the entire watch falls to pieces before he can finish. But when Hora gets interrupted, he doesn’t have to start completely over, just from the last stable subassembly. The result is that Hora makes completed watches about 4,000 times faster than Tempus.
Simon uses this model to illustrate how complex biological systems might have evolved; if a biological system is some assemblage of chemicals, it’s much more likely for those chemicals to come together by chance if some small subset of them can form a stable subassembly. But we can also use the Tempus/Hora model to describe the technological evolution being simulated in Arthur’s paper.
Consider a technology as some particular arrangement of 1,000 different parts, such as the NAND gates that are the basic building blocks of Arthur’s logic circuits. If you can find the proper arrangement of parts, you can build a working technology. Assume we try to build a technology by adding one part at a time, like Tempus and Hora build their watches, until all 1000 parts have been added. In this version, instead of having some small probability of being interrupted and needing to start over, we have a small probability (say 1%) of correctly guessing the next component. This mirrors Arthur’s simulation, where we had a small probability of randomly connecting a component correctly to fulfill some goal. Only by properly guessing the arrangement of each part, in order, can we create a working technology.
In Simon’s original model, assembling a watch was like flipping 1000 biased coins in a row. Each coin had a 99% chance of coming up heads, and only when 1000 heads were flipped was a watch successfully assembled. Our modified model is like flipping 1000 biased coins which have only a 1% chance of coming up heads. Creating a technology via the “Tempus” method is like flipping 1000 coins in a row and hoping for heads each time. The probability of producing a working technology is 0.01^1000, essentially zero. But if we create a technology via the “Hora” method of building it out of stable subassemblies, the combinatorics become much less punishing. Now instead of needing to flip 1000 heads in a row, we only need to flip 10 in a row. 10 successful coinflips — 10 parts successfully added — gives us a stable subassembly, letting us essentially “save our place.” Flipping a tails doesn’t send us all the way back to zero, just to the last stable subassembly. The odds are still low — for each subassembly, you only have a 0.01^10 chance of getting it right — but it’s enormously higher than the Tempus design. You’re much more likely to stumble across a working technology if that technology is composed of simpler stable components, and you can determine whether the individual components are correct.
Arthur’s circuit simulation is able to find complex technologies because it works like Hora, not Tempus: complex circuits are built up from simpler technologies, the way Hora’s watches are built from stable subassemblies. Going from nothing to an 8-bit adder is like Tempus trying to build an entire and very complex watch by getting every step perfect. Much easier to be like Hora, and be the one that only needs to get the next few steps to a stable subassembly correct: adding a few components to a 6-bit adder to get a 7-bit adder, then adding a few to that one to get an 8-bit adder, and so on.
We can illustrate this more clearly with a modified version of Arthur’s circuit search. In this version, rather than trying to fulfill a huge collection of goals, we’re just trying to find the design for a specific 8-bit adder made from 68 NAND gates. Rather than build this up from simpler sub-components (7-bit adders, 6-bit adders, full adders), in this simulation we simply go NAND gate by NAND gate. Each iteration we add a NAND gate, and randomly wire it to our existing set of NAND gates. If we get the wiring correct, we keep it, and go on to try adding the next gate. If it’s incorrect, we discard it and try again.
We can think of this as a sort of modular construction, akin to building a complex circuit up from simpler circuits; at each level, we’re just combining two components, our existing subassembly and one additional NAND gate. This loses verisimilitude, since each subassembly no longer implements some particular functionality (we essentially just dictate that the simulation knows when it stumbles upon the correct gate wiring). But we don’t lose that much: it is, notably, possible to build an 8-bit adder with a hierarchy that requires just two components at almost every level (a few steps require three components). And this simpler simulation has the benefit of making it very easy to calculate the combinatorics at each step.
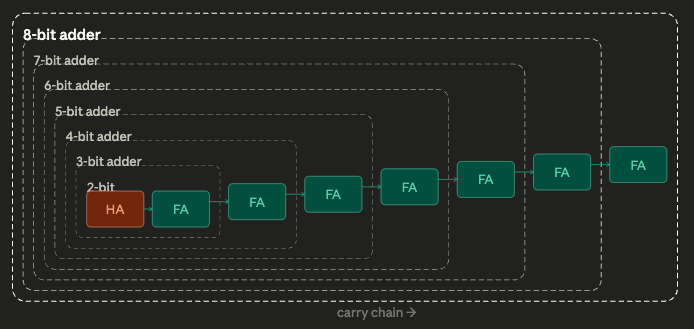
68 NAND gates can create around 2^852 possible wiring arrangements with 16 inputs and 9 outputs. This is much less than the 10^177,554 possibile 16 input and 9 output functions, but it’s still an outrageously enormous number. If we tried to find the right wiring arrangement by random guessing all 68 gates at once, we’d never succeed: even if every atom in the universe was a computer, each one trying a trillion guesses a second, we’d still be guessing for about 10,000,000,000,000…(140 more zeroes)..000 years.
But by going gate-by-gate, the correct arrangement can be found in 453,000 iterations, on average. Each time we add a gate, there’s only a few thousand possible ways that it can be connected, so after a few thousand iterations we guess it correctly, lock the answer in, and move on to the next gate. By determining whether each step is correct, instead of trying to guess the complete answer all at once, the search becomes feasible.
This is why Arthur’s original simulation couldn’t fulfill complex needs without fulfilling simpler needs first: if you try to take too many steps at once, the combinatorics become too punishing, and it becomes almost impossible to find the correct answer by random guessing. In our 68 NAND gate search, finding an 8-bit adder is relatively easy if we go one gate at a time, but if we change that to two gates at a time (randomly adding one gate, then another gate, then checking to see if we’re correct), the expected number of iterations rises from 453,000 to 1.75 billion: if the probability of guessing one gate correctly is 1/1,000, the probability of guessing two gates is 1/1,000,000. If we try to guess three gates at a time (1 in a billion odds of guessing correctly), the number of expected iterations to guess all 68 gates correctly rises to ~9.3 trillion.
The explosive combinatorics gives us a better understanding of some of the results that come out of Arthur’s simulation. For instance, Arthur notes that in each iteration the simulation combines up to twelve components, then checks to see if a working circuit has been found. But Arthur notes that you can vary the maximum value and it doesn’t impact the results of the simulation much, stating of the various simulation settings that “[e]xtensive experiments with different settings have shown that our results are not particularly sensitive to the choice of these parameters.” Indeed, if we re-run the simulation and only allow it to try a maximum of 4 components at once, it works basically just as well as with 12 components. The more random components you combine together, the more the combinatorial possibilities explode, and the lower the chance of finding something useful. The probabilities of finding a useful circuit amongst the various possibilities becomes so immensely low with larger numbers of components that you don’t lose much by not bothering with them at all. Similarly, this also explains another result in the paper, that it’s easier to find complex goals if you specify only a narrower subset of simpler goals related to them. Arthur notes that a complex 8-bit adder is found much more quickly if you only give the simulation a few goals related to building adders. With fewer goals specified, the pool of possible technology components will remain smaller, the number of possible random combinations becomes fewer, and the easier it becomes to find the complex goals.
In essence, using simpler components as stepping stones to more complex ones is a kind of hill-climbing. The simulation looks in various directions (possible combinations of building blocks), until it finds one that’s higher up the hill (finds a circuit that meets some simple goal), restarts the search at the new, higher point on the hill, until it reaches a peak (satisfies a complex goal). The simulation is able to satisfy complex goals because it specified a series of simpler ones that provide a path up the hill to the complex goals. Arthur notes that “[t]he algorithm works best in spaces where needs are ordered (achievable by repetitive pattern), so that complexity can bootstrap itself by exploiting regularities in constructing complicated objects from simpler ones.”
Trying to go to complex circuits directly, then, is akin to just testing random locations in the landscape and seeing if they’re a high point: this is obviously much worse than following the slope of the landscape to find the high points.
Technological search and information
We can sharpen these ideas even further by bringing in some concepts from information theory. Information theory was invented by Claude Shannon at Bell Labs in the late 1940s, and it provides a framework for quantifying your uncertainty, and how much a given event reduces that uncertainty.
I find the easiest way to understand information theory is with binary numbers. The normal math we use day to day uses base 10 numbers. When we count upward from zero, we go from 0 to 9, then reset the first digit to 0 and increment the next digit: 10. With binary, or base 2, we increment the next digit after we get to 1. So 1 in base 10 is 1 in binary, but 2 is 10, 3 is 11, 4 is 100, and so on.
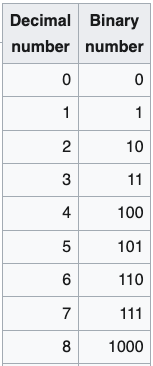
In binary, each binary digit, or bit, doubles the potential size of the number we can represent. So with two digits, we can define 4 possible values (0, 1, 2, and 3 in base 10). With 3 digits, that doubles to 8 possible values (getting us from 0 through 7), with 4 digits that doubles again to 16 possible values, and so on. A 16 bit binary number can represent 2^16 = 65,536 possible values, which is why in computer programming the largest value that a 16 bit integer can represent is 65,535.
Say you have a string of bits, but don’t know whether they’re ones or zeroes. Because each bit doubles the number of possible values that can be represented, each unknown bit you fill in reduces the number of possible values by half. If you have 3 binary digits, there are 8 possible numbers that could be represented. Each time you learn what one of the bits is, you reduce the number of possible values by half.
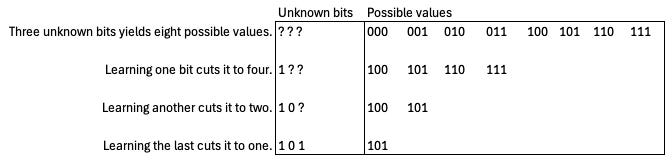
With information theory, we generalize this concept somewhat. In information theory one bit of information reduces the space of possibilities by 50%; in other words, each bit reduces our uncertainty by half. Say you’re like me, and you often lose your phone in your jacket pockets. If you’re wearing a coat with 2 pockets and you know the phone is in one of them, specifying the location of your phone, narrowing it down from 2 possibilities to 1, takes one bit of information. If you’re wearing a coat with 4 pockets, you now need 2 bits of information: 1 bit to tell you whether it’s on the right or the left, and another bit to tell you whether it’s an upper or lower pocket. The first bit cuts the possibilities in half, leaving you with two possibilities, and the second bit cuts it in half again. If your jacket has 8 pockets, now you need 3 bits to specify its location, and so on. The more places that something could be, the more information it takes to specify its location.
Information theory is particularly useful for quantifying how much information we get from some particular outcome. Say someone flips a fair coin; how much information do I get when they reveal whether it was heads or tails? Well, before they reveal it, I knew it could be one of two options, heads or tails. Revealing it narrows the number of possibilities from two down to one. We’ve cut the number of possibilities in half, and thus gained 1 bit of information. More generally, the information provided by some outcome is equal to -log2(the probability of that outcome). So revealing how a fair coin was flipped gives us -log2(0.5) = 1 bit. If we’re dealt a single card from a deck face down, when we reveal that card we’ve reduced the number of possible cards from 52 down to 1, and gained -log2(1/52) = 5.7 bits of information.
For a repetitive process, we also want to know a related quantity: entropy. Entropy is determined by calculating the information received from each possible outcome, multiplying it by the probability of that outcome, then summing all those values together. It’s the expected quantity of information you’ll get by taking some particular action.
Say I’ve lost my phone in my jacket with eight pockets, and am looking for it by randomly trying pockets until I find it. A random guess has a 1/8 chance of successfully finding the phone, and a 7/8 chance of coming up empty. Guessing correctly will yield me -log2(1/8) = 3 bits of information, as expected: once I guess correctly, I know the phone’s location. But an incorrect guess will yield me only 0.19 bits of information: I already knew most of the pockets don’t have the phone, so failing to find the phone in one pocket doesn’t tell me much that I didn’t already know. The entropy of a guess is (1/8) * log2(1/8) + (7/8) * log2(7/8) = 0.54 bits. When I first check a pocket, I can expect to get a little more than half a bit of information. (If I rule out pockets that I’ve already checked, the expected amount of information I get will rise each time, though if you’re like me you might have to check the same pocket a few times before you find the phone.)
Because each bit of information we get cuts the number of possibilities remaining by 50%, it doesn’t take that much information to narrow down an enormously large search space. The 2^852 possible circuits that can be created by wiring up our 68 NAND gates requires only 852 bits — 852 times cutting the number of possibilities in half — to specify. (That’s approximately the same number of bits that it takes to specify each letter of this sentence.)
A key aspect of entropy is that we maximize how much information we get when each outcome is equally plausible. So the entropy of a fair coin, with a 50% chance of coming up heads, is 1 bit. But if the coin has a 90% chance of coming up heads, the entropy is now just 0.46 bits. If the coin has a 99% chance of coming up heads, the entropy falls to 0.08 bits. When one outcome is very likely, you learn much less on each attempt, because you mostly get the outcome you already knew was likely. This is why when playing the game “20 questions,” the most efficient strategy is to try and ask questions where the answer divides the number of possibilities in half. “Is it bigger than a breadbox?” is a good starting question because there are probably roughly similar numbers of items that are bigger and smaller than a breadbox. “Is it a 1997 Nissan Sentra?” is a bad starting question because most possibilities are not a 1997 Nissan Sentra, so we learn very little when the answer is “no.”
We can think of our 68 NAND gate search as flipping a series of very biased coins, each one with a ~ 1/(several thousand) probability of coming up heads (where “heads” is “guessing the right wiring combination for that particular NAND gate”). The entropy of this process — the expected amount of information that we get — is very low, around 0.003 bits per attempt. Each attempt we learn very little about the correct wiring diagram (“it wasn’t this arrangement, it wasn’t this arrangement either, or this one”) so we need a lot of attempts — around 453,000, on average — to accumulate the 852 bits needed to specify the correct wiring for our 8-bit adder.3
Trying to guess two gates at a time is like biasing the coin even further: now each one has a ~1/(several million) probability of coming up heads. We thus get vastly less information per attempt — less than 0.000001 bits per attempt on average — so it takes us many, many more attempts to accumulate the information needed.
A useful way of thinking about our 68 NAND gate search is that it’s like a huge, branching tree. At every step — every time we add a gate — there are thousands of branches, each one representing one possible way to wire up the gate. Each branch then splits into thousands more (representing all the possible ways of wiring up the next gate), which split into thousands more, which split into thousands more, until at the end we have 2^852 possible “leaves,” each one representing a unique way of wiring up all 68 gates. Trying to get all 68 gates right at once, and then checking to see whether or not you did, is like examining one single leaf, one path from the base of the tree all the way to the tip of a branch. Not only are you overwhelmingly likely to guess wrong, but you haven’t narrowed down your possibilities at all: all you know is that one single leaf wasn’t the right answer, leaving you with the rest of the 2^852 possible leaves to sift through.
Checking to see whether each gate we add is correct before we proceed to the next one, by contrast, massively narrows down the number of possibilities. Whenever we determine a gate isn’t in the right spot, it eliminates every possibility that branches off from that point. If there are 1000 possible ways to wire each gate, each time we guess correctly we’ve narrowed down the possibilities downstream of that choicepoint by 99.9%. Huge swaths of possibilities get eliminated at each correct guess, letting us converge on the correct answer much more quickly.
The same basic logic applies to Arthur’s simulation. (In fact, in another publication, Arthur uses a very similar metaphor, describing technological search as trying to find a working path up a mountain, which is full of various obstacles.) Building up complex functions without the aid of intermediate, simpler ones is like trying to find a single leaf on a tree the size of the universe. Building up to complex circuits gradually, using simpler components as building blocks, lets you screen off huge branches of the tree at once. Once you have a working 2-bit adder, every branch that has a non-working 2-bit adder in it gets screened off. Your iterations yield massively more information, and the search problem becomes tractable.
Conclusion
The logic of Arthur’s simulation, and our simpler simulation, also applies to creating new technologies more generally. Logic circuits are a useful model to explore, because they’re real technology that is very amenable to simulation (they have a well-defined, simple behavior), but technology in general can be thought of as a combination of simpler components or elements arranged in various ways to create more complex ones. As Arthur notes:
…in 1912 the amplifier circuit was constructed from the already existing triode vacuum tube in combination with other existing circuit components. The amplifier in turn made possible the oscillator (which could generate pure sine waves), and these with other components made possible the heterodyne mixer (which could shift signals’ frequencies). These two components in combination with other standard ones went on to make possible continuouswave radio transmitters and receivers. And these in conjunction with still other elements made possible radio broadcasting. In its collective sense, technology forms a network of elements in which novel elements are continually constructed from existing ones. Over time, this set bootstraps itself by combining simple elements to construct more complicated ones and by using few building-block elements to create many.
One takeaway from this paper, as Arthur notes and we explored more deeply, is that a hierarchical arrangement of components, where a complex technology is made of simpler components, which are in turn made from even simpler components, makes it much easier to create some new technology. But a more general takeaway is that successfully creating some new technology means getting new information as quickly as possible. Working from (or towards) a hierarchical, modular design for some technology, where each element has some specific job it must do, makes it easier to find new technologies in part because you learn vastly more from each attempt at building one of those subparts. Knowing whether some entire complex function works or not tells you much less than knowing which individual component is working right, and what specific functionality needs to be corrected to fix the problem.
In addition to Brian Arthur, some other folks who I think have done really good work on this are Bernard Carlson, Clay Christensen, Joel Mokyr, Hugh Aitken, Edward Constant, and various folks associated with the Trancik Lab. There’s also a few folks, such as Joan Bromberg and Lillian Hoddeson, who have produced multiple very good technological histories that I return to often.
Indeed, we find that if we just randomly combine dozens of NAND gates, we get a random truth table almost every time, and never solve even medium-complex functions with a few inputs and outputs.
Adding things up, you find that the search actually yields over 900 bits, rather than 852 bits. This is due to the information overhead of a sequential search: you end up getting “extra” information that you don’t need. In our 8-pocket jacket search, if we just guess randomly it will take us on average 8 tries to find the phone. 8 attempts * 0.54 bits per attempt yields 4.32 bits, more than the 3 bits we need to actually specify the phone’s location.
I agree with you wholeheartedly that “the literature on technology is somewhat uneven….if you’re trying to understand the nature of technological progress more generally, the range of good options narrows significantly.”
I think that this is exactly the gap (or one of them actually) that Progress Studies need to fill. Unfortunately, other than you, I have not seen many working on that problem.
Writing yet another case study about a specific technology, organization, or nation is not gong to add much to our knowledge. When the sample size is one, it is hard to identify causality.
What we need is to integrate the hundreds of case studies that already exist into a parsimonious, historically accurate and useful theory that can be applied into the real world today. I have been frustrated with how few Progress Studies writers have even attempted to so (you excluded).
I also agree that Brian Arthur’s Nature of Technology is by far the best theory of technology developed so far. I have a brief summary of that book here:
https://techratchet.com/2020/01/10/book-review-the-nature-of-technology-by-w-brian-arthur/
For those who are interested in a broader view of technological innovation, they might check my series on the topic:
https://frompovertytoprogress.substack.com/p/technological-innovation-the-series
I also have an article on competing theories of Technological Innovation and Diffusion in my larger series on the Pre-History of Progress Studies:
https://frompovertytoprogress.substack.com/p/theories-of-technological-innovation
One thing I like less about Arthur's approach to the problem is how he focuses on the technology itself rather than on the humans who invent the technology. I understand the convenience of that, but I feel the technology will always be downstream of the process of invention — an artifact of progress.
That being said, I believe that finding ledges in the landscape that allow for new abstraction layers in a search through its combinatorial complexity is part of the process of invention and innovation, and the human evidence for that is plentiful.
https://www.symmetrybroken.com/invention-as-exploration/
The biggest open question in technology right now is whether machines will be able to replicate the process that humans have followed for doing this kind of work. There's money at stake, which means motivated reasoning and magical thinking are working hand in hand to obfuscate the problems that remain.
One of the core problem that remains is that we don't yet have an architecture that allows for reliable causal inferencing. The transformers are great at recognizing causal connections that have already been established. They're not currently capable of independent causal reasoning. In reflecting upon how we humans choose what parts of the sparse, high-dimensional landscape to explore, I believe that causal reasoning has been necessary.
The machines cannot tell us where our attention *should* be.